

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- fastapi
- deeplearning
- 랭체인
- 파이썬
- 챗gpt
- 파이토치기본
- MachineLearning
- konlpy
- Python
- 판다스 데이터정렬
- 딥러닝
- 비지도학습
- sklearn
- fastapi #python웹개발
- 파이썬웹개발
- NLP
- 머신러닝
- python 정렬
- programmablesearchengine
- OpenAIAPI
- 판다스
- chatGPT
- 사이킷런
- langchain
- 자연어분석
- fastapi #파이썬웹개발
- pytorch
- HTML
- 파이토치
- pandas
- Today
- Total
Data Navigator
WSL2 Ubuntu에 hadoop 설치하기 본문
WSL2 Ubuntu에 hadoop 설치하기

1.java openjdk-8 설치 및 환경 변수 설정
1) java openjdk-8 설치
sodo apt update
sudo apt-get update
sudo apt-get install openjdk-8-jdk
apt update

apt-get update

java openjdk-8-jdk 설치

2) .bashrc에 JAVA_HOME 추가
vi ~/.bashrc
vi 편집기로 들어오면
i 눌러서 삽입모드로 변형 후 .bashrc 제일 밑에 아래의 경로 추가
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64

JAVA_HOME 경로 설정

esc
:wq 로 저장

3) source ~/.bascrc 로 패스 적용한 것 반영하기
source ~/.bashrc

4) echo $JAVA_HOME 으로 path 경로 확인
echo $JAVA_HOME
2. openssh-server 설치
1) apt-get을 사용해 openssh-server 설치
sudo apt-get install openssh-server
2) 22번 포트 방화벽 해제
sudo ufw allow 22
3) ssh localhost를 입력해 ssh 설정
ssh localhost
혹시 위의 명령어를 입력했는데 아래와 같이 Connection refused가 나오면 ssh 서버가 동작하지 않는 경우이다.

sudo systemctl status ssh로 서버 동작 확인
Acitive 부분이 acitve(running)이 아니면 서버가 죽어있는 것이므로 서버 시동 필요
sudo systemctl start ssh
sudo systemctl status ssh

다시 ssh localhost 실행
ssh localhost
Are you sure you want to continue connection (yes/no/[figngerprint])? 가 나오면 yes

그 후 다시 ssh localhost 입력
ssh localhost
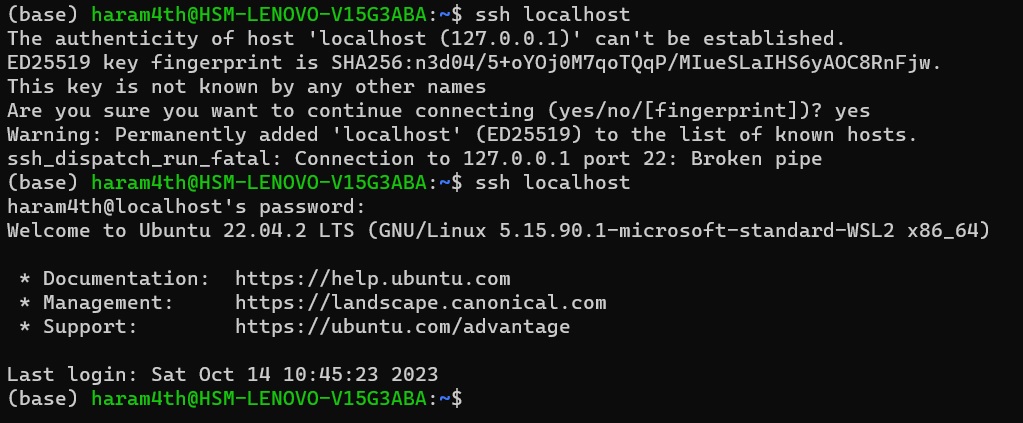
계정 password 입력 후 접속 가능
그런데 나중에 하둡을 설치하면 비번 입력 없이 자동으로 로그인이 되게 해야 하기 때문에 rsa 암호 설정이 필요
4) ssh-keygen으로 암호 생성
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa

5) ls ~/.ssh 로 암호 생성 확인
ls ~/.ssh
6) id_rsa.pub 파일 내용을 ~/.ssh/authorized_keys 에 복사
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
7) cat ~/.ssh/authorized_keys
cat ~/.ssh/authorized_keys

8) chmod 0600 ~/.ssh/authorized_keys 로 authorized_keys 에 rw 권한 부여
chmod 0600 ~/.ssh/authorized_keys
9) 다른 디렉토리로 이동 후 ssh localhost로 접속해 접속이 잘 되는지 확인
cd Downloads 디렉토리로 이동 후 ssh localhost 를 실행하면 디렉토리 위치가 변경되는 것을 확인 할 수 있다.
exit로 빠져나오면 다시 Downloads 디렉토리로 돌아온다.

3. Apache Hadoop 3.3.2 설치
1) google에서 apache hadoop 검색 후 다운로드로 이동

2) 3.3.2 버전을 받기 위해 하단의 mirror site 클릭

3) HTTP 아래 링크 클릭

4) hadoop 3.3.2 버전 다운
wsl에서 설치 할 것이므로 터미널에서 wget을 이용해 다운로드

5) wsl ubuntu 터미널에서 wget으로 hadoop 다운로드
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.2/hadoop-3.3.2.tar.gz
6) ls로 다운로드 받은 파일 확인 후 tar 명령어로 압축 해제
ls
tar zxvf hadoop-3.3.2.tar.gz

7) ls로 압축이 해제되고 hadoop-3.3.2 디렉토리가 생생되었는지 확인

8) hadoop-3.3.2 디렉토리로 이동 후 ls로 파일 확인
cd hadoop-3.3.2
ls
hadoop-3.3.2 디렉토리로 와서 hadoop 이나 hdfs를 쳐보면 명령을 찾을 수 없다고 나온다.
.bashrc에 path 가 설정되지 않아서 나는 오류이므로 .bashrc를 수정해준다.
9) pwd로 현재 위치 경로 출력 후 복사
pwd
출력된 결과를 복사한다
10) .bashrc 에 path 추가
vi ~/.bashrc
i 를 눌러 삽입모드로 변경 후 가장 아래에 path 추가
export HADOOP_HOME=/home/haram4th/hadoop-3.3.2
export PATH=$PATH:$HADOOP_HOME/binesc
:wq로 저장
11) source ~/.bashrc 로 수정사항 적용
source ~/.bashrc
12) hadoop version 명령으로 hadoop 명령이 실행되는지와 버전 확인
hadoop version
4. Hadoop 설정파일 수정하기
1) hadoo-3.3.2 디렉토리 안에 있는 etc 그리고 그 안쪽의 hadoop 디렉토리로 이동한다.
cd ~/hadoop-3.3.2/etc/hadoop
ls 명령어로 안쪽 파일을 보면 여러 개의 xml파일과 sh 파일을 확인할 수 있다.
이중에서 하둡 실행에 필요한 5개의 파일 내용을 수정한다.

2) core-site.xml, hdfs-site.xml, mapred-site.xml, yarn-site.xml, hadoop-env.sh 이렇게 5개를 수정한다.
가. core-site.xml 파일 수정
vi 편집기로 core-site.xml 파일 내용 오픈
vi core-site.xml
i 를 눌러 입력모드로 바꾼 후 아래의 내용을 적어준다.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
esc 로 입력모드 해제 후
:wq 로 저장
나. data와 name 노드 디렉토리 만들기
cd ~/hadoop-3.3.2로 이동해서 dfs 디렉토리를 만들고 그 아래 data와 name 디렉토리를 만든다.
cd ~/hadoop-3.3.2
mkdir -p dfs/data
mkdir -p dfs/name
ls ./dfs/
data, name 디렉토리가 생성된 것을 확인한다.
cd ./dfs/data 로 이동 후 pwd로 경로 출력 후 메모장 등에 경로 저장
cd ./dfs/data
pwd

다. 다시 etc/hadoop 디렉토리로 돌아와 hdfs-site.xml 파일 내용 수정
cd ./etc/hadoop
vi hdfs-site.xml
파일 내용을 아래와 같이 수정하면서 아까 복사해둔 경로를 name에 해당하는 value 부분에 넣어준다.
data 디렉토리를 넣는 부분에도 붙여넣고 name을 data로 변경해 준다.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/haram4th/hadoop-3.3.2/dfs/name</value> # 본인이 생성한 name 디렉토리 경로로 입력
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/haram4th/hadoop-3.3.2/dfs/data</value> # 본인이 생성한 data 디렉토리 경로로 입력
</property>
</configuration>
esc
:wq로 저장
라. mapred-site.xml 파일 수정
vi mapred-site.xml
아래와 같이 내용을 수정한다.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
마. yarn-site.xml 파일 내용 수정
vi yarn-site.xml
아래의 내용을 붙여 넣는다.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
바. hadoop-env.sh 파일 수정
vi hadoop-env.sh
가장 아래에 JAVA_HOME 경로 입력
# JAVA_HOME 추가
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
esc
:wq로 저장
5. hdfs namenode 포멧 하기
hdfs namenode -format

6. hadoop 실행하기
1) cd ~/hadoop-3.3.2/sbin으로 이동 후 명령어 보기
cd ~/hadoop-3.3.2/sbin
ls
2) ./start-dfs.sh 를 실행해 hadoop이 작동하는지 확인
./start-dfs.sh
namenodes, datanodes, secondary namenodes가 정상적으로 출력되는지 확인한다.

3) jps로 hadoop 프로세스가 떠있는지 확인
jps
프로세스가 정상적으로 출력되면 성공이다.
4) 웹브라우저로 하둡 대시보드 확인
웹브라우저 주소창에 localhost:9870 을 입력해서 하둡 대시보드 확인

5) yarn 서비스 실행
./start-yarn.sh
resourcemanager와 nodemanagers가 정상적으로 실행되는지 확인한다.

jps로 프로세스가 떠있는지 확인

6) 웹브라우저에서 yarn 대시보드 확인
웹브라우저 주소창에 localhost:8088 입력하고 yarn 대시보드 확인

정상적으로 작동하는 것을 확인하고 cd ~/hadoop-3.3.2 폴더로 이동한다.
cd ~/hadoop-3.3.2
7. hadoop 예제 파일을 실행해 mapreduce 작동 확인하기
1) ls 명령을 사용해 hadoop-3.3.2 디렉토리 아래 share/hadoop/mapreduce/ 디렉토리를 확인한다.
ls share/hadoop/mapreduce/
2) hadoop jar 명령어를 사용해 하둡 맵리듀스 예제 파일 내용을 출력한다.
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar


3) pi 예제 실행하기
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar pi 5 10000 을 입력해 실행한다.
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar pi 5 10000

출력되는 메세지 중 mapreduce가 정상적으로 실행되는지 확인한다.
4) yarn 대시보드에 접속해서 맵리듀스가 제대로 실행 되었는지 확인한다.

정상적으로 작동하면 성공!!
'WSL, Ubuntu' 카테고리의 다른 글
| wsl2 Ubuntu Anaconda 가상환경에 Tensorflow, cudatoolkit, cudnn 설치하고 gpu 사용하기 (2) | 2023.11.03 |
|---|---|
| WSL2 Ubuntu에 Anaconda 설치 및 path 설정하기 (2) | 2023.10.22 |
| WSL2 Ubuntu 설치, 목록확인, 삭제 (0) | 2023.10.22 |
| WSL2 Ubuntu 한글화 설정 (3) | 2023.10.21 |



